A yearly newsletter about the best debugging project ever
Edition 2, 28 Dec 2012
Contents
- Introduction: growth
- New services
- Into the future!
- Testimonials & conference exposure
- Closing notes
1. Introduction: growth
Today, 28th of december 2012, the RING turns 2 years old! The project’s origins can be traced back to the following line on IRC (translated):
[28 Dec 2010/10:26 CET - #NLNOG]
"hey, maybe we should create a #nlnog test platform"
And now here we are, 2 years later: 188 machines provided by 165 organisations in 39 countries. Compared to 2011 we have more than doubled in size!
From our usage statistics we gather that 65% of organisations actively makes use of the RING through SSH.
Other statistics gathered from our code repositories:
- 1111 commits were made (doubled since last year!)
- Most code commits happened, again, on Tuesdays
- Lines of code: 20267 insertions(+), 5774 deletions(-)
We could not have sustained this level of growth without the continuing support of our infrastructure sponsors and the 2012 fundraiser contributors:
- XS4ALL, Amazon Web Services, Leaseweb, Atrato IP Networks,
- Gossamer Threads, BIT, PCextreme, SoftLayer, Snijders IT,
- Solido Hosting, Duocast, A2B Internet, Nedzone, Tetaneutral,
- LCHost, Previder, Triple IT and eBay Classifieds Group.
A full overview of all supporters can be found here: https://ring.nlnog.net/patrons/
2. New services
AMP (Active Measurement Project):
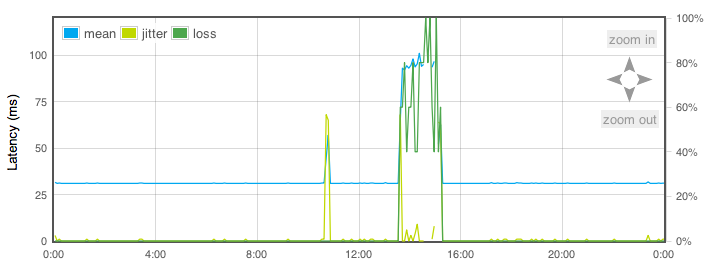
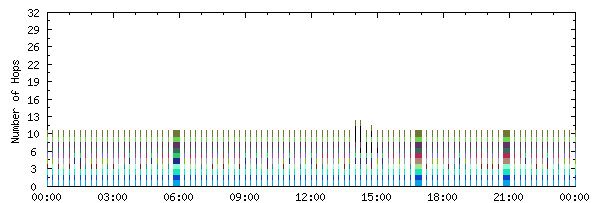
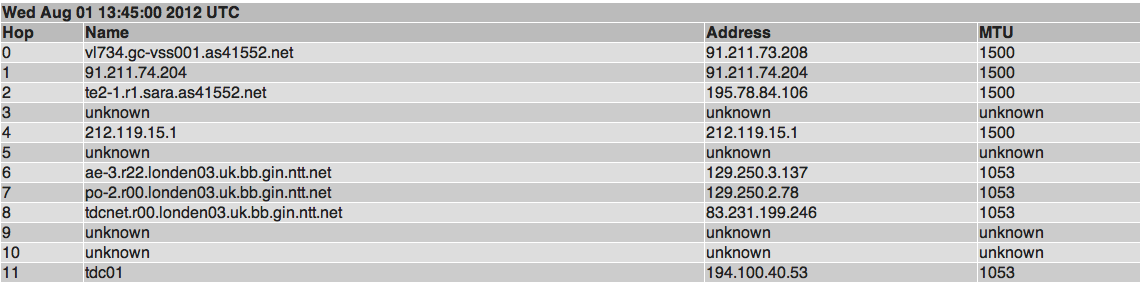
One of the biggest changes this year was moving from a distributed master/slave smokeping setup to something much better: AMP. The AMP software performs measurements from every RING node to every other RING node, and reports the results to central collectors which in turn feed a web interface.
AMP as a tool offers us insight in end-to-end MTU, jitter, latency, packetloss and historic traceroutes both for IPv4 and IPv6 between all RING nodes.
URL: http://amp.ring.nlnog.net/
BGP Looking glass:
Due to popular request we set up a BGP looking glass, which currently receives full IPv4 and IPv6 tables from 35+ participants. The LG uses the BIRD BGP daemon with a web interface written by one of the RING participants!
We currently are exploring if we can use the collected data for a monitoring and alerting system to help participants gain insight in prefix visibility and, for instance hijack events. Stay tuned!
URL: http://lg.ring.nlnog.net/
IRR/RPLS services:
Although the IRR system and RPSL have been around for a long time, there still is a lot of room for improvement in terms of performance, ease of use and standardised methods and tools.
We believe that the RING community can make a difference in the popularity of proper filtering. One of the first things we offer (in beta) is a web service to expand RPSL object such as AS-SET, AUTNUM and RS-SETs and expose the data in JSON.
URL: http://irr.ring.nlnog.net/
3. Into the future!
In 2013 we will continue to automate as many aspects of the RING as possible. But more importantly, the RING has to become the best swiss army knife a network engineer can imagine so we will focus on usability, more advanced tools and security.
We are making a lot of progress towards publication of all kinds of RING related information in an easy accessible database, we imagine this will accelerate the development of a new generation of tools!
We also started talks with other debugging projects such as RIPE Atlas to explore if cooperation and exchange of information can further such projects.
As the RING is a community effort, we can only become more valuable to our members by help from the community. We need you for new creative ideas, high quality code, and of course more RING nodes. If you can help out in our efforts, don’t hesitate to contact us!
4. Testimonials & Exposure
Two debugging cases have been documented, where the RING proved to be of vital importance when debugging an issue at hand.
Route leak:
A root-cause analysis based on historic data collected by the RING.
URL: https://ring.nlnog.net/news/root-cause-analysis-using-amp/
The IPv4 address that ended with .255:
How the variety in RING nodes helped locate an ancient, dysfunctional ACL.
URL: https://ring.nlnog.net/news/ring-success-the-ipv4-255-problem/
Conference exposure:
Various RING participants have spoken at Internet oriented conferences around the world. The following meetings made a presentation slot available to the RING: eduPERT, LINX79, MENOG11, NANOG56 and RIPE65.
All of these presentations have helped the RING grow, as in the days after such a presentation we saw a spike in RING participant applications.
If you want to present about the RING at a meeting in your region or local operator community, please contact us. We have great slides available for this purpose!
5. Closing notes
We conclude this newsletter by saying to you, the participants, THANK YOU! Without the continued support from lots of participants the RING would not be where it is today. We are proud to be playing a small role in making the Internet an easier thing to debug and research.
Again, thank you!
Kind regards,
Job Snijders, Martin Pels, Peter van Dijk, Edwin Hermans, ringthing


")